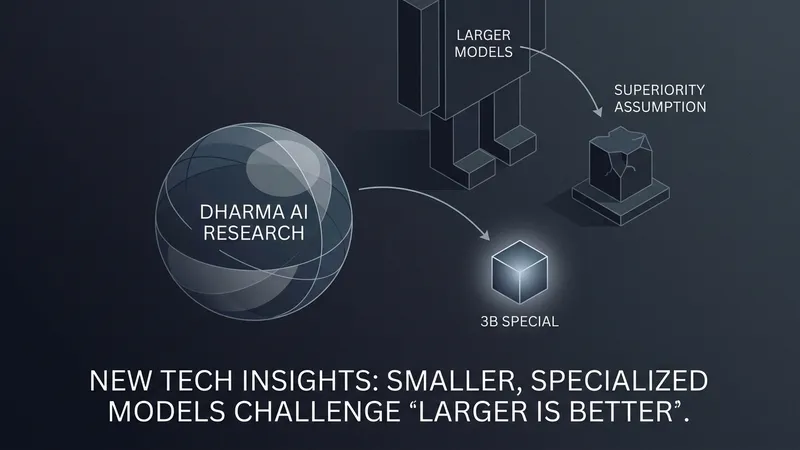
For the past three years, enterprise AI strategy has largely operated on a stable default: the safest choice was usually the largest frontier model available. Smaller models were considered primarily where the workload could tolerate some reduction in quality in exchange for lower cost. The logic behind this assumption was straightforward: capability scaled with parameter count, frontier providers consistently led the major benchmarks, and the cost of choosing the wrong model was perceived as greater than paying a premium for the leading one.
While this reasoning was once defensible, empirical evidence is now challenging this procurement arithmetic. In April, Dharma released DharmaOCR—a pair of specialized small language models for structured OCR, alongside a benchmark and an accompanying paper. The results showed that a 3-billion-parameter model, specialized through a fine-tuning pipeline any well-resourced enterprise could replicate, outperformed every commercial frontier API tested in a well-measured enterprise domain.
Crucially, the performance gap favored the smaller model, while the cost gap ran heavily in the opposite direction. The highest-scoring 3B model was roughly fifty times cheaper to operate than the leading commercial alternatives. This proves that when a model's training history and data distribution are aligned closely with its deployment task, parameter count stops being the decisive variable. It marks a critical turning point where domain specialization compounds to defeat brute-force scaling.
[AgentUpdate Depth Analysis] This research signals a profound paradigm shift for the AI Agent ecosystem. Historically, agent workflows have suffered from high latency and prohibitive costs due to an over-reliance on massive, monolithic frontier models for every sub-task. Dharma's success with specialized 3B models demonstrates that Small Language Models (SLMs) can deliver superior accuracy and deterministic outputs for specific agentic functions like structured parsing, tool calls, and routing. Moving forward, the optimal Agent architecture will shift from a single heavy brain to a decentralized, heterogeneous network of highly-aligned, domain-specific SLMs. This transition drastically reduces inference costs, enables edge deployment, and improves real-time latency, laying the strategic foundation for cost-effective, enterprise-grade AI Agent swarms.