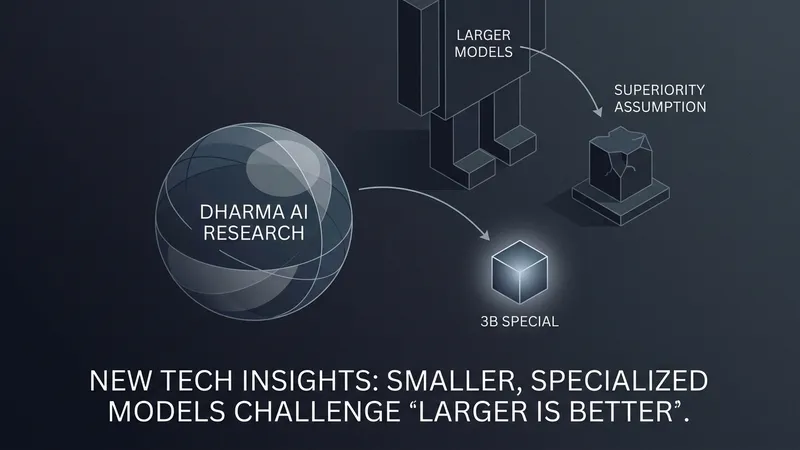
In the evolving landscape of enterprise AI strategy, the prevailing assumption has long been that the safest choice is the largest frontier model available. However, new empirical data from Dharma AI suggests this logic is no longer absolute. When a model's training history is moved close enough to its specific deployment task, parameter count stops being the decisive variable. A 3-billion-parameter specialized model recently outperformed every commercial frontier API tested in a well-measured enterprise domain—at roughly fifty times lower cost.
In April, Dharma released DharmaOCR, a pair of specialized small language models (SLMs) for structured OCR, alongside a benchmark and research paper on Hugging Face. This effort studies how specialization, alignment, and inference economics interact in production AI systems. The key finding is a strategic shift: when specialization is executed correctly, a 3B model doesn't just match larger models; it exceeds them in quality while drastically reducing operational overhead.
For the past three years, the reasoning for choosing massive models was defensible: capability appeared to scale with parameters, and the cost of choosing an inferior model was perceived as higher than the premium for a leading API. Dharma’s benchmark challenges this by showing that a specialized model—developed through a fine-tuning pipeline any well-resourced enterprise could replicate—can win on metrics that matter most to buyers. The highest-scoring model was also the cheapest to operate, altering procurement arithmetic for any meaningful volume.
This result is part of a growing body of research documenting that specialization compounds. When the largest model is not the best-performing model, the variable doing the heavy lifting is distributional alignment. This suggests that for specific, bounded enterprise tasks, the strategic default should shift toward optimized specialization rather than relying solely on the raw scale of general-purpose frontier models.