A common complaint about sandboxing products is that they are rarely thoroughly documented. In the absence of detailed documentation, it's incredibly hard to gauge how much we can actually trust their security claims. Fortunately, Anthropic has just published a fantastic overview detailing how their various sandbox techniques operate across Claude.ai, Claude Code, and Claude Cowork.
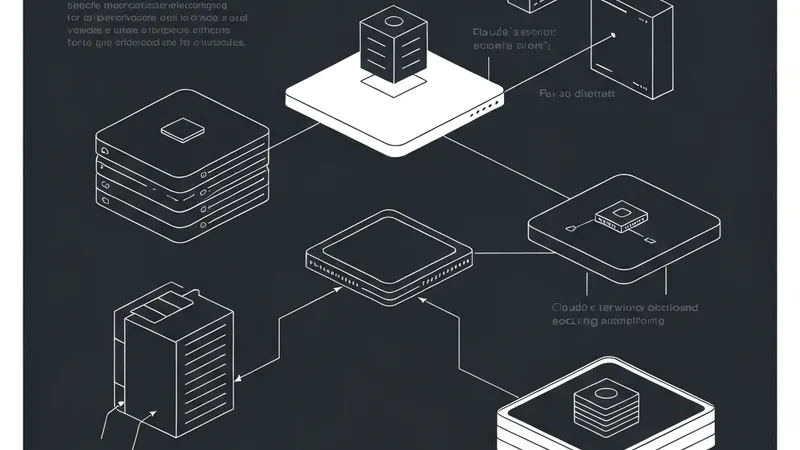
The core strategy involves constraining where and how an AI agent can act using process sandboxes, virtual machines (VMs), strict filesystem boundaries, and robust egress controls. The ultimate goal is to set a hard boundary on what an agent can reach. For instance, if credentials never enter the sandbox in the first place, they simply cannot be exfiltrated—regardless of whether the trigger is a user mistake, a model finding a "creative" unexpected path, or an active attacker.
Depending on the execution environment, Anthropic deploys different sandboxing technologies: Claude.ai utilizes gVisor; Claude Code, which runs locally on user machines, relies on Seatbelt on macOS and Bubblewrap on Linux; meanwhile, Claude Cowork operates inside a full virtual machine (using Apple's Virtualization framework on macOS and HCS on Windows).
The documentation is highly informative, sharing valuable retrospective stories on risks they initially missed, such as the api.anthropic.com/v1/files exfiltration vector that was covered in past security discussions. It also serves as a timely reminder to take another look at Anthropic’s open-source srt (Anthropic Sandbox Runtime) tool—a project that has now matured to a level where it is highly practical for developers looking to run secure LLM code execution environments.
[AgentUpdate Depth Analysis] As AI Agents transition from passive conversationalists to active, code-executing operators, runtime security is becoming the ultimate bottleneck for enterprise adoption. Anthropic’s multi-tiered sandboxing matrix—ranging from container-level gVisor to OS-native Seatbelt/Bubblewrap and hardware-assisted hypervisors—sets a gold standard for LLM-native security engineering. By enforcing the principle of "zero-credential entry inside the sandbox," Anthropic elegantly bypasses the threat of unpredictable prompt injections and logic bypasses. For the broader AI Agent ecosystem, this decoupling of decision-making (the model) and action execution (the sandboxed environment) represents a crucial paradigm shift. Tools like Anthropic's open-source Sandbox Runtime (srt) are poised to become foundational infrastructure, ensuring that next-generation autonomous workflows can run securely without compromising host system integrity.