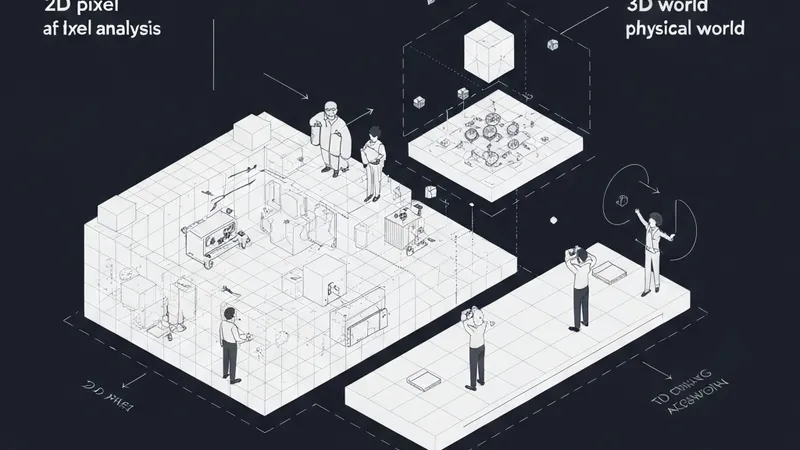
Modern AI systems excel at processing 2D images. They can instantly segment objects in a street scene, generate photorealistic rooms, and describe places they've never seen. However, this capability largely operates in a "flatland" – reasoning about pixels on a 2D grid without an inherent understanding of the 3D physical world those pixels represent.
This critical gap between pixel-level intelligence and true spatial understanding is the single largest bottleneck hindering AI's advancement into real-world applications. Imagine robots navigating warehouses, autonomous vehicles avoiding obstacles, or digital twins accurately mirroring physical buildings; all these require AI to comprehend the genuine 3D environment, not just its 2D projection.
Fortunately, three distinct AI layers are now converging to enable spatial understanding from ordinary photographs. One crucial, often overlooked layer is geometric fusion. This process takes noisy, per-image predictions and transforms them into coherent 3D scene labels. In production pipelines, this can lead to a significant 3.5x label amplification factor, boosting scene coverage from 20% to 78%, effectively making sense of vast amounts of raw data.
While reconstructing 3D geometry from photographs is a largely solved problem—thanks to techniques like Structure-from-Motion pipelines, which have triangulated 3D positions for over two decades, and modern monocular depth estimation models such as Depth-Anything-3 that generate dense 3D point clouds from a single video—the challenge remains in imbuing this geometry with meaning. A point cloud with 800,000 points, however detailed, cannot answer practical questions like "show me only the walls" or "measure the surface area of the floor" without semantic labels.
Producing these semantic labels at scale is notoriously expensive. The traditional approach involves LiDAR scanners and extensive manual annotation, where teams click through millions of points in specialized software. Labeling a single indoor floor of a commercial building can take a trained operator eight to twelve hours, a cost-prohibitive process when scaled to an entire campus or a fleet of vehicles.