当前,现代大语言模型(LLM)的训练范式已不再局限于纯粹的互联网文本数据。越来越多的科技公司正利用强大的“教师”模型来训练更小、更高效的“学生”模型。这一过程被广泛称为LLM蒸馏或模型到模型(model-to-model)训练,已成为以较低计算成本构建高性能模型的关键技术。
例如,Meta曾利用其庞大的Llama 4 Behemoth模型来训练Llama 4 Scout和Maverick;谷歌在开发Gemma 2和Gemma 3时也借力了Gemini模型。类似地,DeepSeek将其DeepSeek-R1模型的推理能力蒸馏到更小的Qwen和Llama系列模型中。
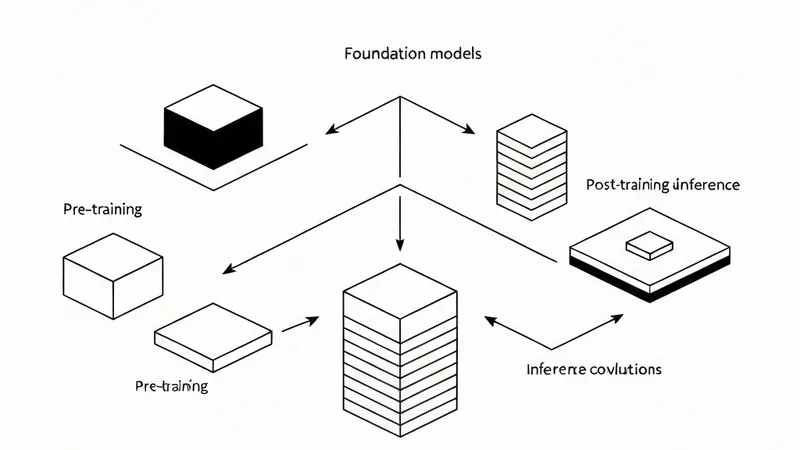
其核心思想很简单:学生模型不仅可以从人类编写的文本中学习,还可以从另一个LLM的输出、概率分布、推理轨迹或行为中汲取知识。这使得较小的模型能够从规模更大的系统中继承推理、指令遵循和结构化生成等关键能力。蒸馏过程可以在预训练阶段进行,即教师模型和学生模型同时训练;也可以在后训练阶段进行,即一个完全训练好的教师模型将知识迁移给一个独立的学生模型。
本文将探讨用于通过一个LLM训练另一个LLM的三种主要方法:软标签蒸馏(Soft-label distillation),学生模型从教师模型的概率分布中学习;硬标签蒸馏(Hard-label distillation),学生模型模仿教师模型生成的具体输出;以及协同蒸馏(Co-distillation),多个模型在训练过程中通过共享预测和行为进行协作学习。
软标签蒸馏
软标签蒸馏是一种训练技术,其中较小的学生LLM通过模仿较大教师LLM的输出概率分布来学习。学生模型不仅仅是学习预测正确的下一个token,而是被训练去匹配教师模型在整个词汇表上的softmax概率分布。例如,如果教师模型预测下一个token时,“cat”的概率为70%,“dog”为20%,“animal”为10%,那么学生模型学习的不仅是最终答案,还包括不同token之间的关系和不确定性。这种更丰富的信息通常被称为教师模型的“黑暗知识”(dark knowledge),因为它包含了关于推理模式和语义理解的隐藏信息。
软标签蒸馏最大的优势在于,它允许较小的模型继承较大模型的能力,同时保持更快的运行速度和更低的部署成本。由于学生模型从教师模型的完整概率分布中学习,与仅从硬性的单词目标学习相比,训练过程更稳定、信息量更丰富。然而,这种方法也伴随着实际挑战。为了生成软标签,你需要访问教师模型的logits或权重,这对于闭源模型通常是不可行的。此外,存储包含10万多个token词汇表中每个token的概率分布,会带来巨大的存储开销。