长期以来,基础模型的“扩展”主要意味着一件事:投入更多计算资源进行预训练,模型能力就会提升。Kaplan等人(2020)的实证研究也支持了这一观点,报告称随着模型参数、数据集大小和训练计算量的扩展,损失函数呈现可预测的幂律趋势。实际上,这些趋势为持续投资大规模加速器容量及其所需的分布式基础设施提供了依据,以确保其高效利用。
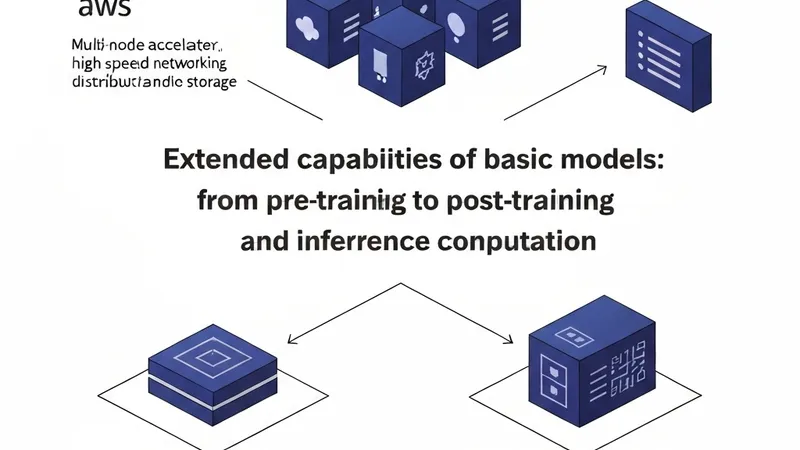
然而,技术前沿已经演进——扩展不再是单一维度。NVIDIA提出的“从一到三的扩展定律”框架,有效地强调了除了预训练之外,模型性能日益通过后期训练(例如,有监督微调(SFT)和基于强化学习(RL)的方法)以及测试时计算(“长时间思考”、搜索/验证、多样本策略)来扩展。
综合来看,这些扩展范式推动了基础模型生命周期——预训练、后期训练和推理——对基础设施的需求趋于一致:紧密耦合的加速器计算、高带宽低延迟网络以及分布式存储后端。同时,它们也提升了资源管理中编排的重要性,以及为维护集群健康和诊断大规模性能问题所需的应用程序和硬件级别的可观测性。
另一个关键趋势是基础模型生命周期日益依赖开源软件(OSS)生态系统,该生态系统涵盖模型开发框架、集群资源管理和运营工具。在集群层面,资源管理通常由Slurm和Kubernetes等系统提供。模型开发和分布式训练普遍通过PyTorch和JAX等框架实现。监控和可视化(即可观测性)通常利用Prometheus进行指标收集,并使用Grafana进行可视化和警报,它们作为基础设施和资源管理之上的操作层。
本文面向参与基础模型训练和推理的机器学习工程师和研究人员,特别关注基于开源框架的工作流。它分析了#AWS基础设施——包括多节点加速器计算、高带宽低延迟网络、分布式共享存储以及相关的托管服务——如何与基础模型生命周期中的常见OSS堆栈进行交互。主要目标是为理解系统瓶颈和扩展提供技术基础。