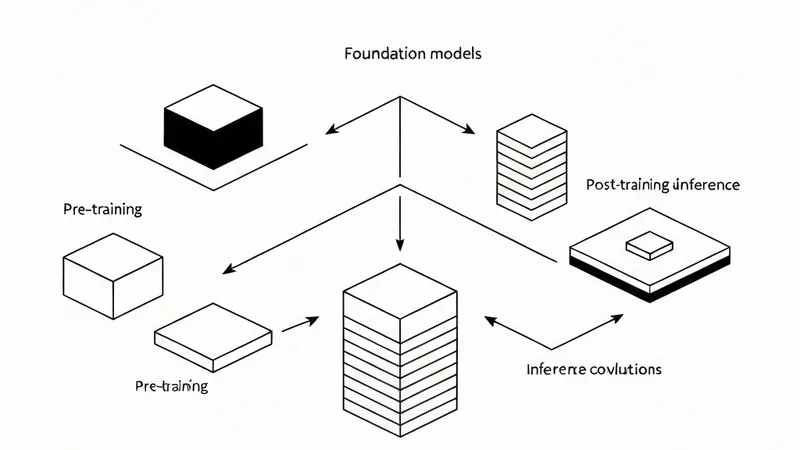
Historically, "scaling" in foundation models primarily implied increasing compute for pre-training to enhance capabilities. Empirical research, such as Kaplan et al. (2020), supported this by demonstrating predictable power-law trends in loss as model parameters, dataset size, and training compute scaled. This understanding justified ongoing investments in significant accelerator capacity and the associated distributed infrastructure for efficient utilization.
However, the frontier has evolved, and scaling is no longer a singular focus. NVIDIA's "from one to three scaling laws" framework highlights that, beyond pre-training, performance increasingly scales through post-training methods (e.g., supervised fine-tuning (SFT) and reinforcement learning (RL)-based approaches) and through test-time compute strategies ("long thinking," search/verification, multi-sample strategies).
Collectively, these scaling regimes drive the foundation model lifecycle—pre-training, post-training, and inference—towards convergent infrastructure demands: tightly coupled accelerator compute, high-bandwidth, low-latency networking, and a distributed storage backend. They also underscore the critical role of orchestration for resource management and the necessity of application- and hardware-level observability for maintaining cluster health and diagnosing performance pathologies at scale.
A significant trend is the growing reliance of the foundation model lifecycle on an open-source software (OSS) ecosystem, encompassing model development frameworks, cluster resource management, and operational tooling. For cluster-level resource management, systems like Slurm and Kubernetes are typical. Model development and distributed training commonly utilize frameworks such as PyTorch and JAX. Observability, including monitoring and visualization, is often handled by Prometheus for metrics collection and Grafana for visualization and alerting, operating as a layer atop infrastructure and resource management.
This article targets machine learning engineers and researchers engaged in foundation model training and inference, with a focus on workflows built upon OSS frameworks. It examines how AWS infrastructure—comprising multi-node accelerator compute, high-bandwidth, low-latency networking, distributed shared storage, and associated managed services—interacts with prevalent OSS stacks throughout the foundation model lifecycle. The primary objective is to lay a technical foundation for comprehending system bottlenecks and scaling challenges.