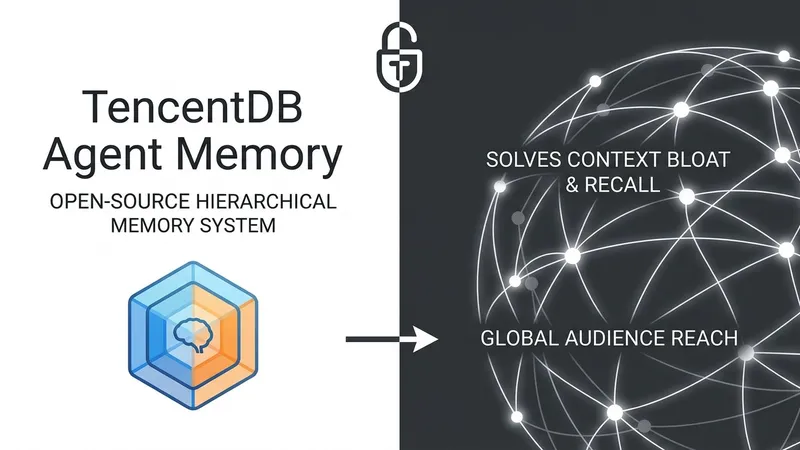
Tencent has released TencentDB Agent Memory, an open-source memory system for AI agents under the MIT license. The project directly targets a problem familiar to anyone shipping long-horizon agents: context bloat and recall failure.
The system combines symbolic short-term memory with layered long-term memory. It integrates seamlessly with OpenClaw as a plugin and with the Hermes Agent through a Gateway adapter. To ensure offline capability and low latency, the default backend uses local SQLite with the sqlite-vec extension, requiring no external APIs.
Why Agent Memory is Hard
Most current memory stacks shred data into fragments and dump them into a flat vector store. Recall then becomes a blind similarity search across disconnected fragments, with no macro-level guidance. The architecture of TencentDB Agent Memory rests on two pillars: memory layering and symbolic memory.
A 4-Tier Semantic Pyramid
For long-term personalization, TencentDB Agent Memory builds a four-level pyramid instead of a flat log: L0 Conversation, L1 Atom, L2 Scenario, and L3 Persona. These levels correspond to raw dialogue, atomic facts, scene blocks, and user profiles, respectively.
The Persona layer carries day-to-day user preferences and is queried first. The system drills down to Atoms or raw Conversations only when finer details are needed. Lower layers preserve evidence, while upper layers preserve structure. Storage is heterogeneous: facts, logs, and traces are persisted in databases for full-text retrieval, while personas, scenes, and canvases are stored as human-readable Markdown files under ~/.openclaw/memory-tdai/.
Symbolic Short-Term Memory via Mermaid
Long-running agent tasks consume massive tokens through verbose tool logs, search results, code, and error traces. TencentDB Agent Memory addresses this through context offloading combined with symbolic memory.
Full tool logs are offloaded to external files under refs/*.md. State transitions are encoded in Mermaid syntax inside a lightweight task canvas. The agent reasons over this symbol graph within its context window. When it needs the raw text, it simply greps for a node_id and retrieves the corresponding file. The Tencent development team describes this as a deterministic drill-down from top-layer symbol to mid-layer index to bottom-layer raw text.
Benchmark Numbers
Results were measured over continuous long-horizon sessions to simulate realistic context-accumulation pressure (such as running 50 consecutive tasks per session in SWE-bench).
On WideSearch, integrating the plugin with OpenClaw raised the pass rate from 33% to 50% (a 51.52% relative improvement), while token usage dropped from 221.31M to 85.64M (a 61.38% reduction). On SWE-bench, the success rate climbed from 58.4% to 64.2% while tokens fell from 3474.1M to 2375.4M (a 33.09% reduction). On AA-LCR, the success rate moved from 44.0% to 47.5%, with a 30.98% token reduction. For long-term memory, PersonaMem accuracy rose from 48% to 76%.
[AgentUpdate Depth Analysis] Traditional AI Agent memory frameworks rely heavily on flat vector databases, which often suffer from context dilution and high token costs during long-horizon executions. TencentDB Agent Memory breaks this bottleneck by shifting from naive semantic search to a highly structured, symbolic, and tiered architecture. By implementing a 4-tier semantic pyramid and Mermaid-based symbolic execution graphs, it introduces a deterministic reasoning path that minimizes LLM context pressure. Compared to generic memory solutions like Mem0 or standard LangChain memory, Tencent's approach is localized (via SQLite/sqlite-vec) and optimized for low-latency, complex workflow management. This shift from messy vector similarity to structured symbolic cognition marks a significant step forward in making autonomous agents reliable enough for enterprise-grade deployment.