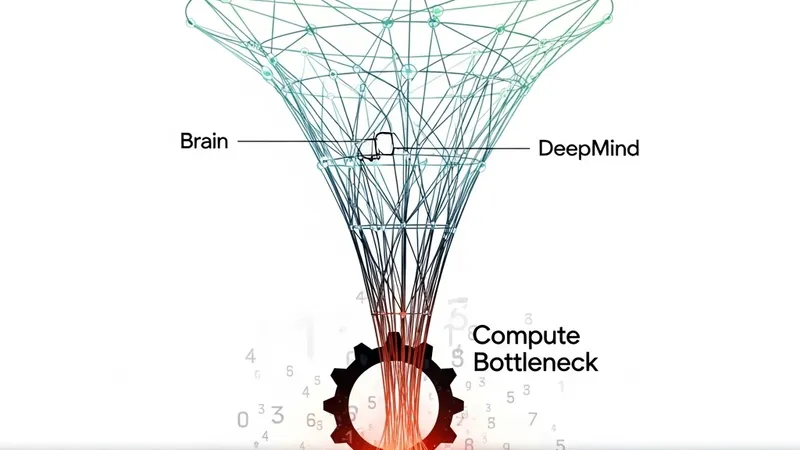
According to sources familiar with the matter, AI researchers inside Google are grappling with an unprecedented compute crisis. Despite Google possessing one of the world's most sophisticated data center networks and proprietary TPU (Tensor Processing Unit) clusters, the skyrocketing demand for multimodal LLMs and autonomous AI Agents has forced internal teams to fiercely lobby for hardware access.
Following the consolidation of Google Brain and DeepMind into Google DeepMind, allocating computational resources has become a highly politicized process. Researchers must now present detailed proposals to an internal committee to secure precious TPU time. While this centralized approach optimizes efficiency, it has reportedly stifled grassroots innovation, pushing long-term AI Agent research behind immediate commercial priorities like Gemini model iterations.
As the AI paradigm shifts towards embodied intelligence and reasoning-heavy agents, the demand for both training and inference-time compute has escalated exponentially. This persistent bottleneck raises concerns about talent retention, as top-tier researchers seek more agile environments in compute-rich startups.
[AgentUpdate Depth Analysis] The internal friction at Google underscores a fundamental truth: compute has become the ultimate bottleneck for the next generation of AI Agents. True autonomous agents require extensive reinforcement learning (RL) and search-based inference (System 2 thinking), which are incredibly compute-intensive. Google’s struggles hint that raw hardware accumulation is no longer enough. To unblock the Agent ecosystem, the industry must pivot from brute-force scale to architectural efficiency—leveraging protocols like MCP for decentralized compute, or optimizing local-edge inference to distribute the massive cognitive load of multi-agent networks.


