In the quest to build autonomous AI Agents, the memory system serves as the foundational cornerstone for achieving true cognitive agency. To equip agents with long-term memory, developers heavily rely on vector databases. However, implementing vector retrieval for agent memory introduces unique engineering and theoretical challenges, specifically surrounding HNSW limitations, forgetting mechanisms, and budget management.
The Dynamic HNSW Dilemma
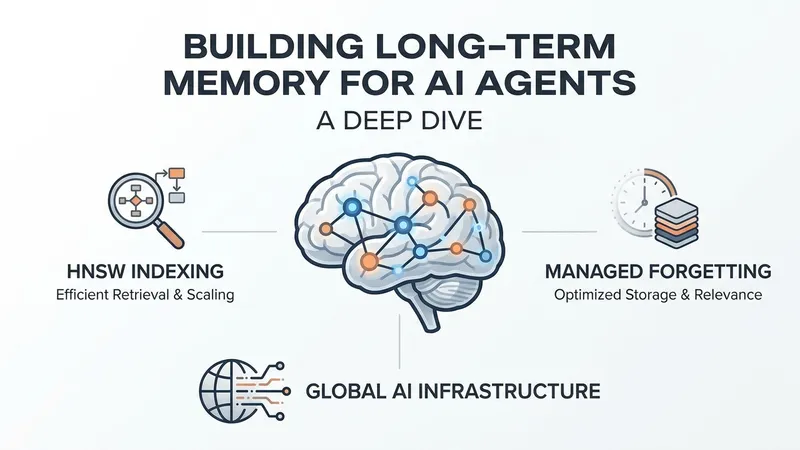
Hierarchical Navigable Small World (HNSW) is the gold standard for approximate nearest neighbor (ANN) search in mainstream vector databases like Milvus, Qdrant, and Pinecone. Designed for "write-once, read-many" static retrieval, HNSW achieves incredible lookup speeds by building multi-layer graph structures. However, agent memory is highly dynamic, requiring frequent insertions, updates, and deletions of memories. For HNSW, physical deletion degrades graph connectivity. Most databases rely on "tombstoning" (soft deletion), which eventually degrades index quality and search precision, forcing expensive reindexing cycles.
Engineering the Mechanism of Forgetting
An agent cannot retain every raw piece of information indefinitely; doing so leads to context window pollution and semantic noise. Thus, a structured "forgetting" mechanism is critical. Modern approaches include: 1) Temporal Decay: Adjusting similarity scores using a decay function to deprioritize older memories; and 2) Semantic Consolidation: Leveraging LLMs to cluster and synthesize fragmented, historical memory vectors into unified, high-level summaries, freeing up vector nodes while retaining the core semantic substance.
Managing Memory Budgets
Agents operate under strict constraints: token limits, API costs, and latency. Managing this memory budget requires a tiered storage architecture, akin to computer hardware. Short-term working memory is stored directly in the LLM context; episodic memory is managed via sliding windows; and long-term semantic memory resides in the vector database. When querying, agents must use adaptive thresholds and dynamic K-truncation to balance retrieval quality with token costs.
[AgentUpdate Depth Analysis] Looking at agent architecture through the lens of operating systems, agent memory is shifting from static, read-only RAG patterns to highly dynamic read-write cycles. The HNSW limitation highlighted here exposes a fundamental mismatch between current static vector database designs and the dynamic state-management requirements of active AI Agents. Moving forward, dedicated agent memory frameworks like Letta (formerly MemGPT) and Mem0 will likely decouple semantic memory management from raw vector indexes. The industry must move beyond blunt HNSW tombstoning toward native support for temporal decay, graph-based pruning, and dynamic consolidation. Designing lightweight, self-optimizing memory architectures that mimic human synaptic pruning is not just a performance optimization—it is the ultimate path to low-latency, cost-effective, and highly autonomous AI Agent ecosystems.