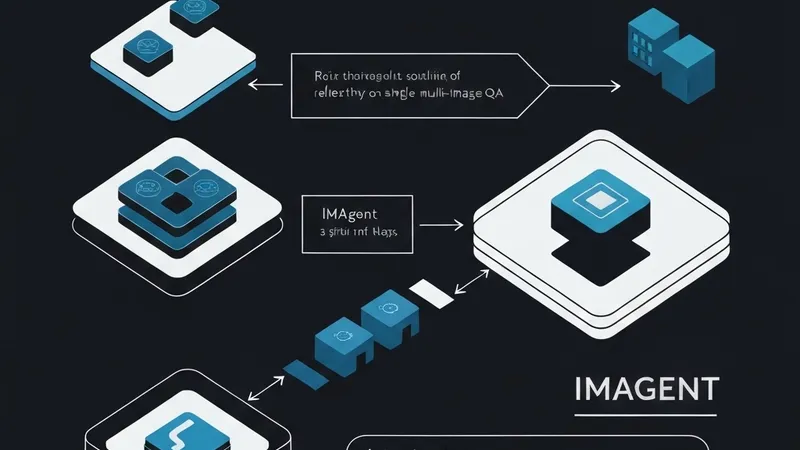
Recent advancements in VLM-based agents, aiming to emulate OpenAI O3's "thinking with images" through tool use, often face a significant limitation: most open-source methods restrict inputs to a single image. This inherent constraint severely curtails their applicability to complex, real-world multi-image question-answering (QA) tasks.
To address this critical gap, researchers introduce IMAgent, an innovative open-source visual agent. IMAgent is distinguished by its training methodology, employing end-to-end reinforcement learning for fine-grained reasoning across both single and multi-image scenarios. A core challenge in VLM inference is the tendency of models to gradually neglect visual inputs over time. IMAgent tackles this by integrating two specialized tools: visual reflection and verification. These tools empower the model to actively re-focus its attention on the image content, ensuring sustained visual processing.
Beyond its robust architecture, IMAgent provides a novel insight into agent performance. For the first time, this work elucidates how strategic tool usage can enhance an agent's capabilities from an attention perspective. The agent's effective tool-use paradigm is acquired through pure reinforcement learning, facilitated by a carefully designed two-layer motion trajectory masking strategy and a specific tool-use reward gain. This approach eliminates the need for expensive supervised fine-tuning data, a common bottleneck in AI development.
To further unlock the inherent tool-usage potential of its base VLM and bridge existing data gaps, the team constructed a challenging, visually rich multi-image QA dataset using a multi-agent system. Extensive experiments rigorously validate IMAgent's superior performance, achieving state-of-the-art (SOTA) results across mainstream single and multi-image benchmarks. The in-depth analysis presented offers actionable insights, significantly contributing to the broader AI community. Code and data for IMAgent are slated for an upcoming release.