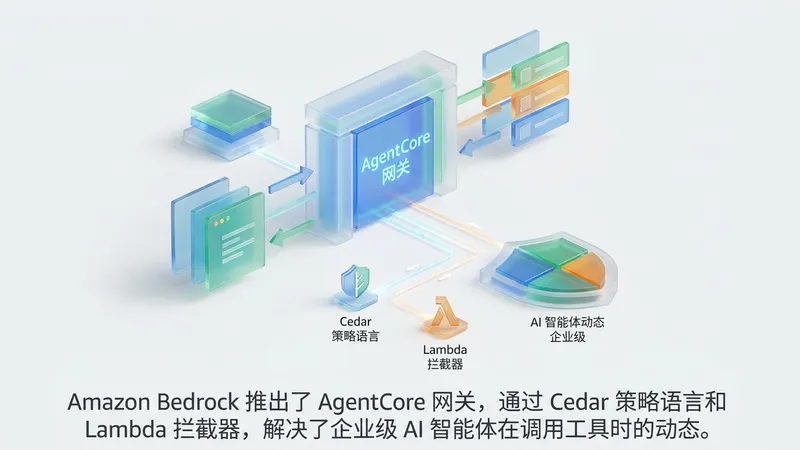
随着企业大规模部署 AI 智能体(AI Agents)以实现工作流自动化,如何安全地管理数以千计的工具调用成为了核心挑战。传统的静态应用逻辑无法应对 LLM 在运行时动态决定调用工具、参数及执行顺序的需求。为了解决这一治理难题,Amazon Bedrock 引入了 AgentCore 网关,通过两种互补机制保障智能体行为安全。
首先是 Amazon Bedrock AgentCore Policy。该机制基于 Cedar 声明式策略语言,允许开发者定义主体(Principal)、动作(Action)和资源(Resource)之间的访问逻辑。它能够对每一个请求进行确定性的“允许”或“拒绝”判定,并自动生成审计日志,从而满足企业合规性要求。
其次是 Lambda Interceptors(Lambda 拦截器)。这一机制支持在工具调用前后执行自定义代码,不仅能够实现动态验证,还支持有效载荷(Payload)增强、令牌交换及响应过滤。通过结合 Policy 的确定性管控与 Lambda 的灵活动态验证,开发者可以构建起分层防御体系。
本文通过一个湖仓数据智能体案例展示了其实际应用:系统根据地理位置和角色权限(保单持有人、理赔员、管理员)对数据访问进行严苛限制。通过在 AgentCore 网关中组合使用 Policy 和 Lambda,确保了即便在大规模 Agent 生态中,数据访问依然具备高安全性与审计可追溯性。
【AgentUpdate 深度解析】 随着 Agent 从单体任务演进为多 Agent 协作网络,传统的 IAM 权限管理已无法覆盖动态的 Agent 决策路径。Amazon Bedrock AgentCore 的核心价值在于将“安全治理”从应用层剥离至网关层,这标志着 AI 原生架构向“基础设施级治理”的进化。相比于传统的 API Gateway,AgentCore 引入的 Cedar 策略语言是治理的灵魂——它允许在语义层面进行访问控制,而非仅仅是基于路由。这种“确定性策略 + 动态执行钩子”的架构,实际上是 AI Agent 生态中对于“LLM 护栏(Guardrails)”的延伸。横向对比来看,这种架构为企业提供了类似 MCP(Model Context Protocol)的统一标准,能够有效抑制 Agent 在自动化推理过程中产生幻觉或越权调用。未来,随着 Agent 复杂度的提升,这种基于网关的安全模式将成为企业级 Agent 部署的事实标准,为 Agent 规模化落地消除信任障碍。


