在大规模部署大语言模型(LLM)时,可观测性已成为生产级机器学习策略中不可或缺的核心支柱。与返回确定性输出的传统软件不同,LLM 生成的响应具有波动性和自由格式,这使得标准指标难以对其进行验证。随着输入数据分布的变化,LLM 的输出质量会随时间发生漂移,而质量监控有助于及早发现这些变化。对于生成式 AI 工作负载,可观测性还必须涵盖模型服务基础设施,其中不可预测的 Token 消耗、GPU 显存压力以及延迟激增,使得容量规划和成本控制变得难以捉摸。
全面大模型推理可观测性必须解决两个截然不同但又互补的维度:模型服务基础设施(“量”的维度)和大模型输出质量(“质”的维度)。系统量能监控侧重于推理基础设施的运行健康状况,追踪请求吞吐量和资源利用率。这些指标有助于检测性能瓶颈、合理调整计算资源并控制成本。质量监控则专注于 LLM 自身的实际表现,评估其随着时间推移的响应准确性、合规性和一致性。
大多数技术团队会分阶段构建 LLM 可观测性体系。第一阶段是建立对核心运行指标(如延迟、错误率和资源利用率)的可见性。这些信号能够确认推理终端的可靠性。第二阶段则通过采样和评估引入 LLM 质量监控,从而揭示模型漂移、性能衰退或生成响应中的异常行为。
当两个维度的监控都准备就绪后,开发者可以引入结合了基础设施和质量信号的阈值与自动告警。随着时间的推移,这一实践将延伸到跨模型和配置的对比分析,从而持续优化成本、性能和输出质量。量能与质量指标是相互依存的:一个推理终端在运行指标上可能非常健康,但却持续输出低质量或不安全的响应;反之,它也可能在过度配置的基础设施上低效运行,却交付高质量的输出。只有当这两个维度被共同监控、相互关联并协同优化时,生产级的 LLM 可观测性才会真正显现。
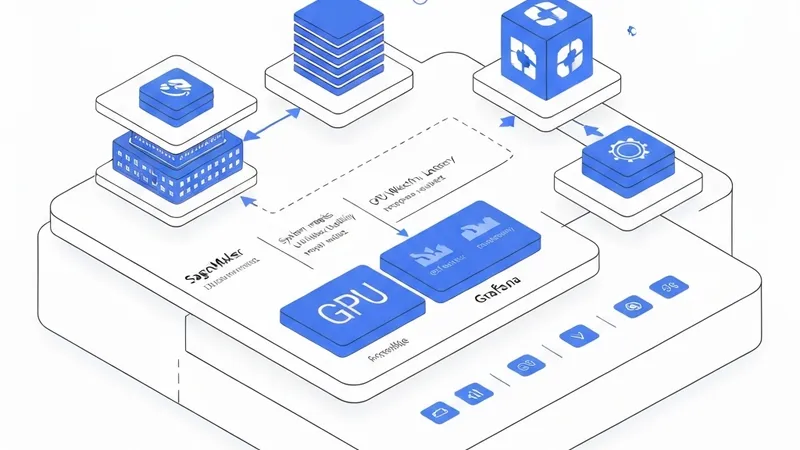
本方案展示了如何利用 Amazon Managed Grafana 仪表板构建全面的可观测性解决方案,针对在 Amazon SageMaker AI 推理组件上运行的大语言模型,提供质量和量能两个维度的全景视图。整个工作流架构主要由三个核心 AWS 服务构建,各司其职:包含推理组件的 Amazon SageMaker AI 终端、Amazon CloudWatch 以及 Amazon Managed Grafana。
【AgentUpdate 深度解析】在大模型应用(尤其是 AI Agent)加速落地的当下,传统的“黑盒”调用模式正面临严峻挑战。AI Agent 依赖多步推理和工具链调用,任何微小的基础设施延迟或模型幻觉,都会在复杂的 Agent 决策链路中级联放大。本方案提出的“量能(Quantity)+质量(Quality)”双维度观测框架,为 Agent 开发者提供了一个关键的设计范式。横向对比 LangSmith 或 Phoenix 等垂直端到端 Agent 观测工具,AWS SageMaker 方案更侧重于云原生基础设施的稳定与成本控制。对于企业级 Agent 生态而言,这种将底层 GPU/Token 消耗与上层 Agent 决策质量协同监控的能力,是实现从“Demo 实验”走向“高并发生产级部署”的必经之路。未来,支持多 Agent 协同(Multi-Agent)链路追踪与动态算力调度的可观测性标准,将成为云厂商的核心竞争壁垒。