条件图像编辑旨在根据文本提示和可选的参考指导来修改源图像,这在需要严格结构控制的场景中至关重要,例如在驾驶场景中插入异常物体或进行复杂的人体姿态变换。
尽管近年来大型编辑模型(如Seedream、Nano Banana等)取得了显著进展,但大多数方法仍依赖于单步生成范式。这种方法通常缺乏明确的质量控制,可能导致图像过度偏离原始内容,并频繁产生结构性伪影或与环境不一致的修改,通常需要大量手动提示调整才能获得可接受的结果。
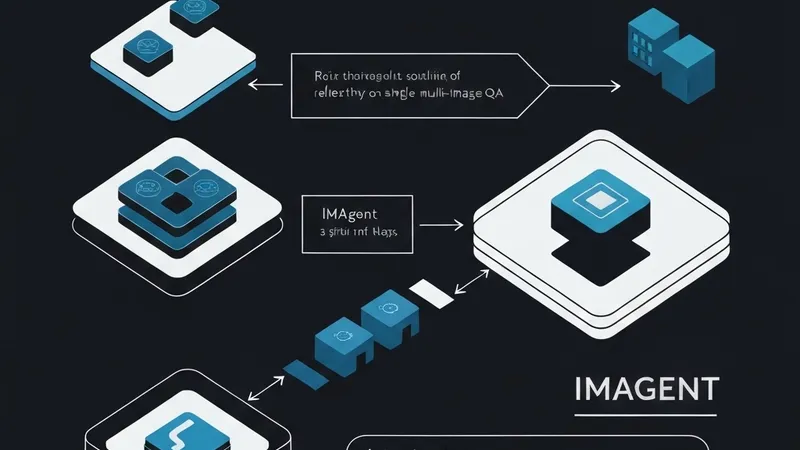
为了解决这些问题,研究人员提出了CAMEO,一个结构化的多智能体框架,它将条件编辑重新定义为一个质量感知、反馈驱动的过程,而非一次性生成任务。CAMEO将编辑任务分解为规划、结构化提示、假设生成和自适应参考接地等协调阶段,仅当任务复杂性需要时才调用外部指导。
为克服现有方法中内在质量控制的缺失,CAMEO将评估直接嵌入到编辑循环中。中间结果通过结构化反馈进行迭代细化,形成一个闭环过程,逐步纠正结构和上下文不一致性。CAMEO在异常插入和人体姿态切换任务上进行了评估。结果显示,在多个强大的编辑骨干网络和独立的评估模型上,CAMEO的平均胜率比多个最先进的模型高出20%,这表明其在条件图像编辑方面显著提高了鲁棒性、可控性和结构可靠性。