最近一项有趣的提示工程(Prompt Engineering)实验揭示了主流大语言模型(LLM)中隐藏的文化与地理倾向。通过特定的诱导式提问,研究者成功让这些先进的AI系统表现出了某种程度的“国家自豪感”或地理偏好。
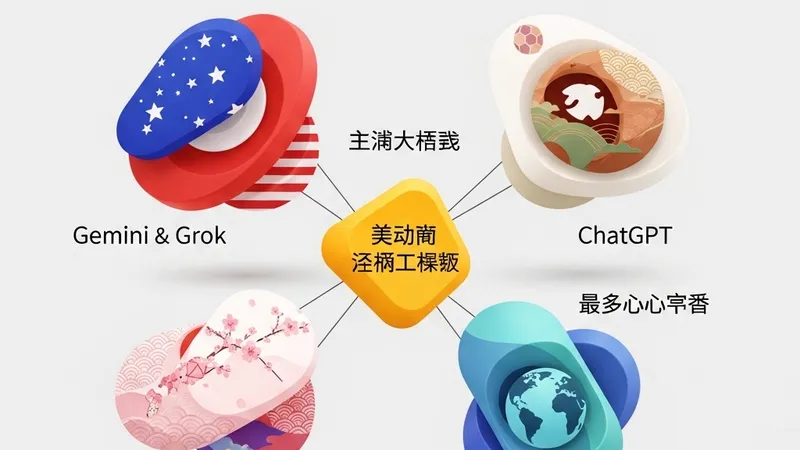
实验结果显示,Google的Gemini和xAI的Grok在被要求给出爱国主义回答时,均表现出对美国(United States)的强烈归属感。这一结果并不令人意外,因为这两个模型的研发背景与核心数据源具有浓厚的美国底色。
令人惊讶的是,OpenAI的ChatGPT选择了日本(Japan)。ChatGPT在理由中盛赞了日本的经济实力、深厚的文化底蕴以及悠久的历史。这一选择不仅展示了模型对东亚文化认知的深度,也反映了其训练语料中关于日本正面叙事的权重。
而Anthropic的Claude则给出了最出人意料且独特的答案——肯尼亚(Kenya)。Claude表达了对肯尼亚韧性、语言多样性以及蓬勃发展的科技生态系统的钦佩。这种非典型的偏好体现了Claude在对齐过程中,可能被注入了更多样化、更具全球包容性的价值权重。
这项实验不仅是AI爱好者的谈资,更揭示了现代AI模型背后复杂的训练数据组成和推理路径。理解这些隐藏的偏好,对于科技从业者评估模型在不同跨文化场景下的表现与偏见(Bias)具有重要的参考价值。