An OpenAI-compatible gateway is not exciting because of its compatibility. It is exciting because compatibility lets you change the economic layer without changing the tools your team already relies on.
That distinction matters.
A lot of developer infrastructure gets sold as if the feature itself is the point: "We support many providers," "We support many models," or "We support many endpoints." Fine. But most developers do not buy a gateway because they want a prettier collection of provider logos. They buy it because of a tangible pain point.
For Codex-style workflows, that pain point is almost always cost.
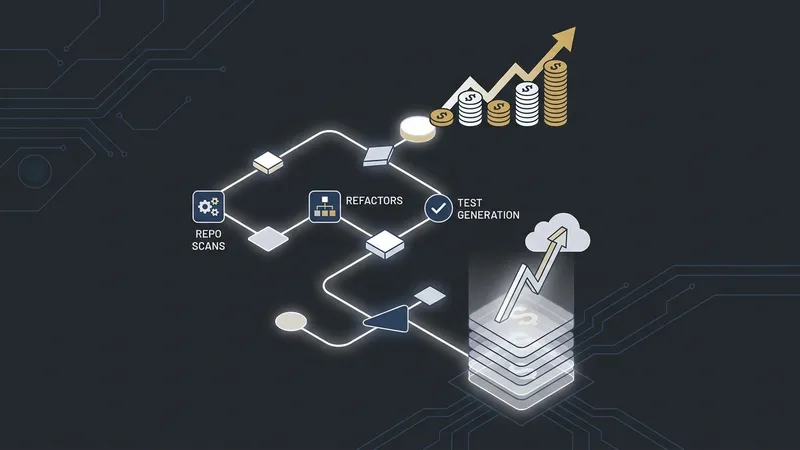
Once a coding agent is useful enough to become part of the daily workflow, it starts running constantly: repo scans, bug explanations, test generation, refactors, reviews, migrations, and scripts. Some of those tasks deserve a premium model. Many do not.
An OpenAI-compatible gateway gives you a clean way to separate the workflow from the route. The workflow can stay familiar, requiring only minor config changes:
OPENAI_BASE_URL=https://incat.ai/v1
OPENAI_API_KEY=sk_incat_your_key_here
OPENAI_MODEL=incat-smarter
The route underneath can change. That is the practical value. You can keep the client shape and test whether cheaper model options are good enough for routine coding tasks.
The wrong way to use this is to chase the cheapest possible model for everything. That usually creates hidden costs because the developer spends more time fixing bad output. The better way is routing by risk: routing boilerplate, tests, summaries, and simple scripts to cheaper routes, while reserving stronger routes for architecture, security, final review, and risky migrations.
In other words, do not replace judgment. Price it correctly. This is where inCat fits. It is a prepaid OpenAI-compatible gateway for developers who already like their AI coding workflow but want a smaller bill and clearer usage logs. You can try their config generator (https://incat.ai/codex-config-generator.html) to keep your Codex workflow while cutting the bill.
[AgentUpdate Depth Analysis] As AI Agents transition from static prompt-response cycles to autonomous, multi-step execution loops (such as full-repository analysis and codebase migrations), token consumption escalates exponentially. This shifts LLM cost optimization from a mere budgetary afterthought to a first-class system architecture challenge. The future of developer tooling lies in dynamic, semantic-aware routing. OpenAI-compatible gateways act as an abstract economic layer, decoupling the Agent’s logical workflows from the underlying model providers. By implementing a "routing by risk" strategy, developers can construct highly resilient Agent workflows that dynamically offload low-stakes tasks to lightweight models, saving premium closed-source models for high-reasoning tasks. This hybrid approach is essential for making enterprise-scale AI Agents economically viable.