Understanding the inner workings of Large Language Models (LLMs) often involves wading through complex mathematics. However, by tracking the journey of a single token rather than getting bogged down in equations, we can demystify the mechanics of AI inference. This approach offers a brilliantly accessible mental model for grasping modern Natural Language Processing (NLP).
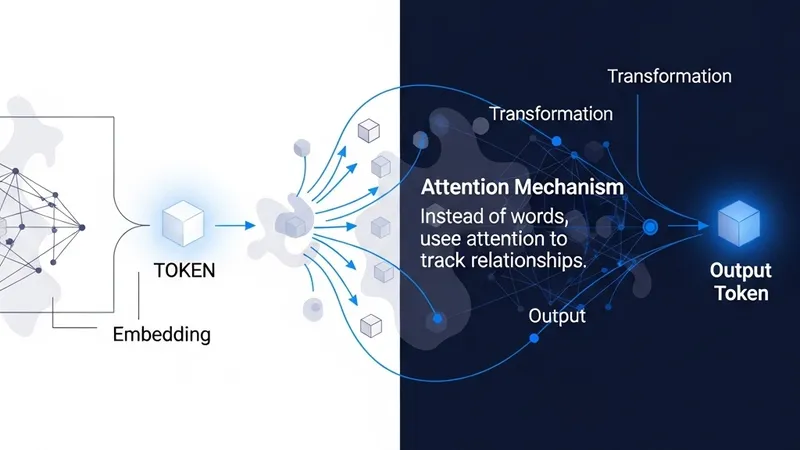
The process begins when text is broken down into tokens and converted into embedding vectors. These vectors serve as the foundational mathematical representation of language. The model operates not by processing literal words, but by continuously transforming these numerical arrays through its successive layers.
The Attention mechanism acts as the primary tool for determining relevance. It identifies which earlier tokens are most important to the current context, allowing the model to gather information from the sequence's history. This creates a dynamic flow of information that updates the state of each token as it passes through the network.
The key simplification is that the model is not "thinking in words." It is repeatedly rewriting vectors until the last vector is useful enough to predict what comes next. Each layer refines the mathematical representation until a final prediction can be made, highlighting the core efficiency and complexity of transformer-based architectures.


