The term "World Model" has become one of the most popular yet heavily abused concepts in AI, representing everything from video generators to game engines and physics engines. To address this lack of precision, AI pioneer Dr. Fei-Fei Li recently published an article providing a clear, functional taxonomy for world models.
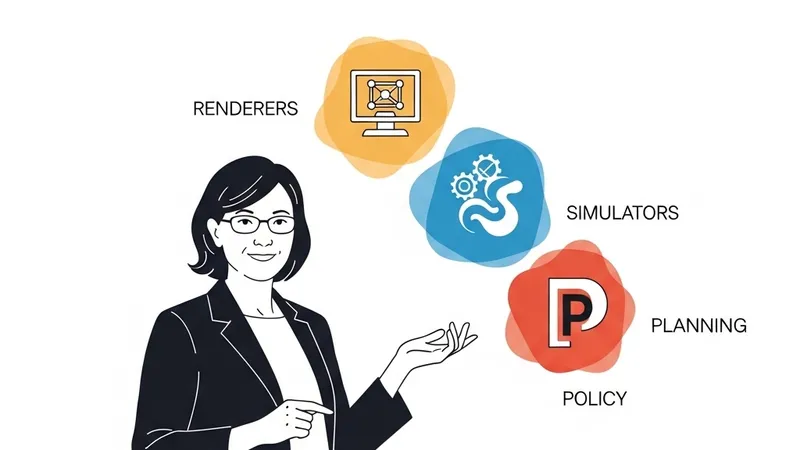
Dr. Li points out that just as the ancient Greeks struggled to define "the world" because it is not a single entity, modern AI requires conceptual precision. Technically, a world model operates in a closed loop: an agent takes an action that affects the world's "state" (a complete description of reality at a given moment), and the agent perceives this reality via "observation" to plan its next action. Current systems labeled as world models are simply different projections of this loop. Dr. Li categorizes world models into three key functions: Renderers, Planners, and Simulators.
First, Renderers take actions and output visual observations for humans, optimizing for visual fidelity. Examples include Google’s Genie 3 and World Labs' RTFM. These models lack an explicit understanding of 3D structures, prioritizing visual realism over physical accuracy. While commercially mature, their outputs cannot yet be utilized in high-precision domains like architecture or robotics training.
Second, Planners ingest observations and goals to output actions. VLA (Vision-Language-Action) models and next-generation world action models fall into this category, defining what robots should do in unstructured environments. Despite massive capital influx and impressive embodied AI demos, planners remain mostly constrained to limited laboratory environments, struggling with the complexity and duration required for real-world deployment.
Third, Simulators output computable, interactive states, prioritizing geometric, physical, and dynamical consistency. They serve professional creators needing precision beyond visual aesthetics, and act as safe training grounds for reinforcement learning, robotics, and autonomous driving. Dr. Li emphasizes that simulation is the bridge connecting rendering and planning. If language is abstraction and pixels are projection, then geometry, physics, and dynamics are the world itself. Despite huge market potential (e.g., NVIDIA's Omniverse), simulators suffer from severe 3D data scarcity, sim-to-real gaps, and high multi-physics simulation costs. World Labs' new project, Marble, attempts to address this by accepting multimodal inputs to generate explorable 3D environments and collision meshes, though it is just the beginning.
Crucially, Dr. Li argues that the boundaries between these three models are dissolving. A model that truly understands the physical world should be able to render it from any angle, simulate its physical reactions, and plan actions. Recent research shows pre-trained video renderers can serve as backbones for joint world and action predictions. World Labs' Marble, outputting both Gaussian splats (for rendering) and collision meshes (for simulation), exemplifies this convergence. The logical end state is a unified foundation world model that simultaneously renders photorealistic views, generates physically accurate structures, and plans action sequences, though challenges in data scaling and reconciling visual aesthetics with physical precision remain.
[AgentUpdate Depth Analysis] Dr. Fei-Fei Li's deconstruction of world models offers a critical roadmap for the evolution of physical AI Agents. By separating and then integrating rendering, simulation, and planning, she defines the technical stack required for next-generation embodied agents. Traditionally, AI Agents have been limited to text-based cognitive tasks. To interact with the physical world, agents need more than a planning brain; they require a "Simulator" to predict physical consequences and a "Renderer" to visualize outcomes. This shift toward "Spatial Intelligence" will enable agents to operate in unstructured physical environments, unlocking multi-trillion-dollar industries like autonomous driving and humanoid robotics. Ultimately, this unified framework transforms AI Agents from passive text-analyzers into active physical decision-makers.