With the explosive growth of AI, researchers face a daily deluge of new academic papers. To solve this, this guide details an automated literature research pipeline built with arXiv API and Gemini 1.5 Flash, delivering personalized paper summaries straight to LINE.
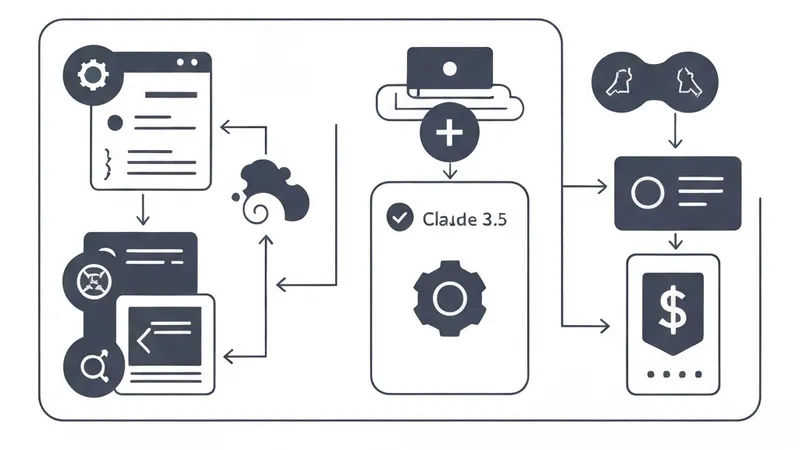
The core architecture relies on three steps. First, an automation runner like GitHub Actions triggers a cron job to fetch the latest papers using the arXiv API based on targeted categories (e.g., `cs.AI`, `cs.LG`).
Next, the metadata is piped into Google #Gemini API. Leveraging Gemini's cost-efficient context window and high reasoning capability, the system condenses complex abstracts into clear bullet points highlighting key contributions and methodologies.
Finally, the summarized reports are formatted using LINE Messaging API's Flex Message format. This provides users with a clean, responsive UI to read key insights and open PDF links directly from their mobile devices.
[AgentUpdate Depth Analysis] From the AI Agent ecosystem perspective, this "information-triage" micro-agent represents a shift towards proactive knowledge workflows. While heavy multi-agent frameworks like CrewAI or LangGraph are powerful, lightweight single-agent workflows integrated directly into communication platforms like Slack or LINE offer massive advantages in latency and operational cost. By leveraging Gemini 1.5 Flash's fast inference, researchers can bypass manual curation. In the long term, we expect these agents to evolve from static push notifications to interactive research partners. Integrating with protocols like MCP (Model Context Protocol), such agents will soon bridge the gap between citation managers (like Zotero), runtime coding sandboxes, and vector databases, unleashing fully autonomous end-to-end scientific discovery engines.